计算机网络笔记-第二章-应用层
[TOC]

一、前言
⚡写了第一章的笔记以后发现如果所有的笔记都写的话工作量有点大,所以从第二章开始就只记录一些重点的以及不熟悉的知识点啦,并不会全部记录~好伐啦让我们一起进入计算机网络-第二章🔥
二、应用层协议原理
网络应用的体系结构
- 客户-服务器模式(C/S模式)
- 服务器
- 一直运行
- 固定的IP地址和周知的端口号(约定)
- 扩展性:服务器场–数据中心进行扩展且扩展性差
- 客户端
- 主动与服务器通信
- 与互联网有间接性的连接
- 可能是动态IP地址
- 不直接与其他客户端通信
- 服务器
- 对等体(P2P)体系结构
- (几乎)没有一直运行的服务器
- 任意端系统之间可以进行通信
- 每一个节点既是客户端又是服务器
- 自扩展性-新peer节点带来新的服务能力,当然也带来新的服务请求
- 参与的主机间歇性连接且可以改变IP地址
- 例子:迅雷
- C/S 和 P2P体系结构的混合体
- Napster
- 文件搜索:集中
- 主机在中心服务器上注册其资源
- 主机向中心服务器查询资源位置
- 文件传输:P2P
- 文件搜索:集中
- 即时通信
- 在线检测:集中
- 当用户上线时,向中心服务器注册其IP地址
- 用户与中心服务器联系,以找到其在线好友的位置
- 两个用户的聊天:P2P
- 在线检测:集中
- Napster
- 客户-服务器模式(C/S模式)
进程通信
- 客户端进程:发起通信的进程
- 服务器进程:等待连接的进程
- 在同一个主机中,使用进程通信机制通信
- 不同主机通过交换报文进行通信
- 使用OS(操作系统)提供的通信服务
- 按照应用协议交换报文
- 借助传输层提供的服务
- 注意:P2P架构的应用也有客户端和服务器进程之分
分布式进程通信需要解决的问题
- 进程标识和寻址问题(服务用户)
- 进程为了接收报文,必须有一个标识,即SAP(发送也需要标识)
- 主机:唯一的32位IP地址
- 仅仅用IP地址不能够唯一的标识一个进程,在一台端系统上有很多应用进程在运行
- 采用的传输层协议:TCP or UDP
- 端口号(Port Numbers)
- 下面是一些知名端口号例子
- HTTP:TCP 80
- Mail:TCP 25
- ftp:TCP 2
- 下面是一些知名端口号例子
- 一个进程用IP+Port标识端节点
- 本质上,一对主机进程之间的通信由2个端节点构成
- 主机:唯一的32位IP地址
- 进程为了接收报文,必须有一个标识,即SAP(发送也需要标识)
- 进程标识和寻址问题(服务用户)
传输层提供的服务-需要穿过层间的信息
- 层间接口必须要携带的信息
- 要传输的报文(对于本层来说:SDU)
- 谁传的:己方的应用进程的标示:IP+TCP(UDP)端口
- 传给谁:对方的应用进程的标示:对方的IP+TCP(UDP)端口
- 传输层实体(TCP或UDP实体)根据这些信息进行TCP报文段(UDP数据报)的封装
- 源端口号,目标端口号,数据等
- 将IP地址往下交IP实体,用于封装IP和数据报:源IP和目标IP
- 层间接口必须要携带的信息
传输层提供的服务-层间信息的代表
- 如果Socket API每次传输报文,都携带如此多的信息,太繁琐易错,不便于管理->使用套接字
- 用个代号标示通信的双方或者单方:socket
- TCP socket这里先不说,后面会有详细的说明
- UDP socket这里先不说,后面会有详细的说明
应用层协议:定义了:运行在不同端系统上的应用进程如何相互交换报文
- 交换的报文类型:请求和应答报文
- 各种报文类型的语法:报文中各个字段及其描述
- 字段的语义:字段取值的含义
- 进程何时、如何发送报文以及对报文进行响应的规则
- 应用协议仅仅是应用的一个组成部分
- Web应用:HTTP协议、web客户端、web服务器、HTML
- 应用协议仅仅是应用的一个组成部分
应用层需要传输层提供什么样的服务?如何描述传输层的服务?
数据丢失率
- 有些应用要求100%的可靠数据传输,例如文件
- 有些应用,例如音频,能荣仍一定比例数据的丢失
延迟
- 延迟、延迟差,比如电话,打游戏的延迟
吞吐
- 一些应用,例如多媒体,必须需要最小限度的吞吐,从而使得应用能够有效的运转
- 一些应用能够充分利用可供使用的吞吐(弹性应用)
安全性
机密性
完整性
可鉴别性

TCP服务
- 可靠的数据传输服务
- 流量控制:发送方不会淹没接收方
- 拥塞控制:当网络出现拥塞时,能抑制发送方
- 不能提供的服务:时间保证、最小吞吐保证和安全
- 面向连接:要求客户端进程和服务器进程之间建立连接
UDP服务
- 不可靠的数据传输服务
- 不提供的服务:可靠、流量控制、拥塞控制、时间、带宽保证、建立连接
UDP存在的必要性
- 能够区分不同进程,而IP服务不能
- 在IP提供的主机到主机端到端功能的基础上,区分了主机的应用进程
- 无需建立连接
- 不做可靠的工作,例如检错重发
- 没有拥塞控制和流量控制,应用能够按照设定的速度发送数据
- 而在TCP上面的应用,应用发送数据的速度和主机向网络发送的实际速度是不一致的,因为有流量控制和拥塞控制
- 能够区分不同进程,而IP服务不能
安全TCP
- TCP&UDP
- 都没有加密
- SSL
- 在TCP上面实现,提供加密的TCP连接,具有私密性,数据完整性,端到端的鉴别
- SSL在应用层,使用SSL库,而SSL库使用TCP通信
- SSL socket API 应用将明文交给socket,SSL将其加密并在互联网上传输
- TCP&UDP
三、Web and HTTP
HTTP是无状态的
- 服务器并不会维护关于客户的任何信息
维护状态的协议很复杂
- 必须维护历史信息状态
- 如果服务器/客户端死机,它们的状态信息可能不一致,二者的信息必须是一致
- 无状态的服务器能够支持更多的客户端
HTTP连接
- 非持久的HTTP
- 最多只有一个对象在TCP连接上发送
- 下载多个对象需要多个TCP连接
- HTTP/1.0 使用非持久性连接
- 非持久的HTTP特点
- 每个对象要2个RTT
- RTT (Round Trip time):从客户端发送一个很小的数据包到服务器并返回所经历的时间。
- 操作系统必须为每个TCP连接分配资源
- 但浏览器通常打开并行TCP连接,以获取引用对象
- 每个对象要2个RTT
- 持久HTTP
- 多个对象可以在一个(在客户端和服务器之间的)TCP连接上传输
- HTTP/1.1 默认使用持久连接
- 持久HTTP特点
- 服务器在发送响应后,仍保持TCP连接
- 在相同客户端和服务器之间的后续请求和响应报文通过相同的连接进行传送
- 客户端在遇到一个引用对象的时候,就可以尽快发送该对象的请求
- 非流水式的持久HTTP
- 客户端只能在收到前一个响应后才能发出新的请求
- 每个引用对象花费一个RTT
- 流水式的持久HTTP
- HTTP/1.1的默认模式
- 客户端遇到一个引用对象就立即产生一个请求
- 所有引用(小)对象只花费一个RTT是可能的
- 非持久的HTTP
HTTP请求报文
- 两种类型的HTTP报文:请求、响应
- 相关方法类型:GET、POST、HEAD、PUT、DELETE
HTTP响应状态码
他们位于服务器->客户端的响应报文的首行
200 OK 请求成功,请求对象包含在响应报文的后续部分
301 Moved Permanently
请求的对象已经被永久转移了,新的URL在响应报文的Location,首部行中指定
客户端软件自动用新的URL去获取对象
400 Bad Request 一个通用的差错代码,表示该请求不能被服务器解读
404 Not Found 请求的文档在该服务上没有找到
505 HTTP Version Not Supported
用户-服务器状态:cookies 大多数主要的门户网站使用cookies
- 四个组成部分
- 在HTTP响应报文中有一个cookies的首部行
- 在HTTP请求报文含有一个cookies的首部行
- 在用户端系统中保留有一个cookies文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
- Cookies能带来什么
- 用户验证
- 购物车
- 推荐
- 用户状态
- 如何维护
- 协议端节点:在多个事务上,发送端和接收端维持状态
- cookies:http报文携带状态信息
- Cookies与隐私
- Cookies允许站点知道许多关于用户的信息、
- 可能将它知道的东西卖给第三方
- 使用重定向和cookies的搜索引擎还能知道用户更多的信息
- 如通过某个用户在大量站点上的行为,了解其个人浏览方式的大致模式
- 广告公司从站点获得信息
- 四个组成部分
Web缓存
目标:避免每次都访问服务器,减少服务器的工作需求
- 在缓存中的对象:缓存直接返回对象
- 如对象不在缓存,缓存请求原始服务器,然后再将对象返回给客户端
- 缓存既是客户端又是服务器
- 通常缓存是由ISP安装(大学、公司、居民区ISP)
- 为什么要使用Web缓存?
- 降低客户端的请求响应时间
- 可以大大减少一个机构内部网络与Internet接入链路上的流量
- 互联网大量采用了缓存;可以使较弱的ICP也能够有效提供内容
- 条件GET方法
- 目标:如果缓存器中的对象拷贝是最新的,就不要发送对象
- 缓存器:在HTTP请求中指定缓存拷贝的日期
- 服务器:如果缓存拷贝陈旧,则响应报文没包含对象
四、FTP*
感觉不是很重要,就贴图把!
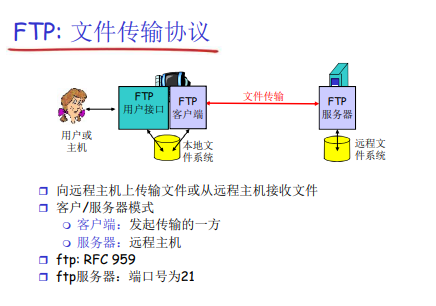


五、Email
老规矩,贴图~




六、DNS
- DNS(Domain Name System -> 计算机域名)
- IP地址标识主机、路由器
- IP地址不好记忆,存在着“字符串”向IP地址转换的重要性
- 人类用户提供要访问机器的“字符串”名称
- 有DNS负责转换成为二进制的网络地址
- DNS的历史
- APPANET的名字解析解决方案
- 主机名:没有层次的一个字符串(一个平面)
- 存在着一个(集中)的维护站:维护着一张主机名-IP地址的映射文件:Hosts.txt
- 每台主机定时从维护站取文件
- APPANET解决方案的问题
- 当网络中主机数量很大时
- 没有层次的主机名称很难分配
- 文件的管理、发布、查找很麻烦
- 当网络中主机数量很大时
- APPANET的名字解析解决方案
- DNS的总体思路和目标
- 主要思路
- 分层的、基于域的命名机制
- 若干分布式的数据库完成名字到IP地址的转换
- 运行到UDP之上端口号为53的应用服务
- 核心的Internet功能,但难以在应用层实现
- 在网络边缘出来复杂性
- 主要目的
- 实现主机名-IP地址的转换
- 其他目的
- 主机别名到规范名字的转换:Host aliasing
- 邮件服务器别名到邮件服务器的正规名字的转换:Main server aliasing
- 负载均衡 load Distribution
- 主要思路
- DNS系统需要存在的问题
- 设备命名
- 用有意义的字符串,方便记忆与使用
- 解决一个平面的重名问题:层次化命名
- 名字到IP地址的转换
- 分布式的数据库维护和响应名字查询
- 如何维护增加或删除一个域,需要在域名工作中做什么
- 设备命名
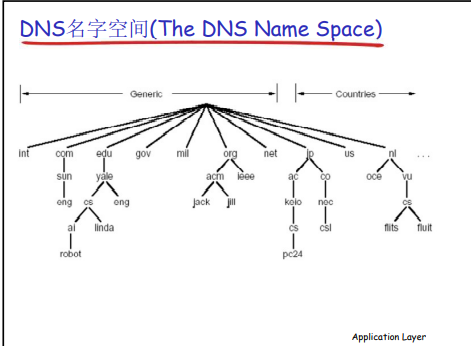
- DNS名字空间
- DNS域名结构
- 一个层次命名设备会有很多重名
- DNS采用层次树状结构的命名方法
- Internet根被划为几百个顶级域(top lever domains)
- 通用的
- .com;.edu;.gov;.int;.web
- 国家的
- .cn;.us;.nl;.jp
- 通用的
- 每个(子)域下面可划分为若干子域
- 树叶是主机
- DNS名字空间
- 域名(Domain Name)
- 从本域往上,直到树根
- 中间使用“.”间隔不同的级别
- 例如:xatu.edu.cn
- 域的域名:可以用来表示一个域
- 主机的域名:一个域上的主机
- 域名的管理
- 一个域管理其下的子域
- .jp被划分为ac.jp cp.jp
- .cn被划分为edu.cn com.cn
- 创建一个新的域必须要征得它所属域的同意
- 一个域管理其下的子域
- 域与物理网络无关
- 域遵从组织界限,而不是物理网络
- 一个域的主机可以不在一个网络
- 一个网络的主机不一定在一个域
- 域的划分是逻辑的,而不是物理的
- 域遵从组织界限,而不是物理网络
- DNS域名结构
- 解析名字-名字服务器(Name Server)
- 一个名字服务器的问题
- 可靠性问题:单点故障
- 扩展性问题:通信容量
- 维护问题:远距离的集中式数据库
- 区域
- 区域的划分由区域管理者自己决定
- 将DNS名字空间划分为互不相交的区域,每个区域都是树的一部分
- 名字服务器
- 每个区域都有一个名字服务器:维护着他所管辖区域的权威消息
- 名字服务器允许被放置在区域之外,以保障可靠性
- 名字空间划分为若干区域Zone

- 权威DNS服务器:组织机构的DNS服务器,提供组织机构服务器可访问的主机和IP之间的映射,组织机构可以选择实现自己维护或某个服务提供商来维护
- 顶级域(TLD)服务器:负责顶级域名(如com, org, net, edu和gov)和所有国家级的顶级域名(如cn, uk, fr, ca, jp )
- Network solutions 公司维护comTLD服务器
- Educause公司维护eduTLD服务器
- 区域名字服务器维护资源记录
- 资源记录
- 作用:维护域名-IP地址(其他)的映射关系
- 位置:Name Server的分布式数据库中
- RR格式
- Domain_name:域名
- Ttl:time to live:生存时间(权威,缓冲记录)
- Class类别:对于Internet,值为IN
- Value值:可以是数字,域名或ASCII串
- Type类别
- Type=A:Name为主机,Value为IP地址
- Type=CNAME:Name为规范名字的别名,Value为规范名字
- Type=NS:Name为域名(如foo.com),Value为该域名的权威服务器的域名
- Type=MX:Value为name对应的邮件服务器的名字
- TTL:生存时间->决定了资源记录应当从缓存中删除的时间
- 资源记录
- 一个名字服务器的问题
- DNS大致工作过程

贴图贴图


这样做,一旦服务器学到了一个映射,就将该映射缓存起来。根服务器通常都在本地服务器中缓存着,使得根服务器不用经常被访问,可以达到提高效率的目的。可能会存在缓存结果和权威资源记录不一致。解决情况:TTL(默认聊天)
- 新增一个域需要维护的问题
- 在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名和域名服务器的地址
- 在新增子域的名字服务器上运行名字服务器,负责本域的名字解析:名字–>IP地址
- 例子:在com域中建立一个“Network Utopia”
- 到注册登记机构注册域名networkutopia.com
- 需要向该机构提供权威DNS服务器(基本的、和辅助的)的名字和IP地址
- 登记机构在com TLD服务器中插入两条RR记录: (networkutopia.com, dns1.networkutopia.com, NS) (dns1.networkutopia.com, 212.212.212.1, A)
- 在networkutopia.com的权威服务器中确保有
- 用于Web服务器的www.networkuptopia.com的类型为A的记录
- 用于邮件服务器mail.networkutopia.com的类型为MX的记录
七、P2P应用
纯P2P架构
- 没有(或极少)一直运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网,每次IP 地址都有可能变化
- 例子:
- 文件分发(BitTorrent - > 洪流)
- 流媒体(KanKan)
- VoIP(Skype)
嗯这个应用这一块我自己有蛮多不理解的,就不记录了,到时候让自己百度加深印象和理解吧。
八、CDN
这一部分嗯贴贴图吧。



九、TCP套接字(Socket)编程
我们知道,TCP是可靠的、字节流的服务
- TCP socket:
- TCP服务,两个进程之间的通信之前需要建立连接
- 两个进程的连接会持续一段时间,通信关系稳定
- 可以用一个整数表示两个应用实体之间的通信关系,本地标识
- 穿过层间接口的信息量最小
- TCP socket:源IP,源端口,目标IP,目标端口
- TCP服务,两个进程之间的通信之前需要建立连接
- TCP套接字4元组是一个具有本地意义的标识
- 4元组:源IP,源端口,目标IP,目标端口
- 唯一的指定了一个会话(2个进程之间的会话关系)
- 应用使用的这个标示,与远程的应用进程通信
- 不必在每一个报文的发送都要指定这4元组
- 就像使用操作系统打开一个文件,OS返回一个文件句柄一样,以后使用这个文件句柄,而不是使用这个文件的目录名、文件名
- 简单,便于管理


十、UDP套接字编程
我们知道,UDP是不可靠的(数据UDP数据报)服务
UDP socket
- UDP服务,两个进程之间的通信需要之前无需建立连接
- 每个报文都是独立传输的
- 前后报文可能给不同的分布式进程
- 因此,只能用一个整数表示本应用实体的标示
- 因为这个报文可能传给另外一个分布式进程
- 穿过层间接口的信息大小最小
- UDP socket:本IP,本端口
- 但是传输报文时:必须要提供对方的IP,port
- 接收报文时:传输层需要上传对方的IP,port
- UDP服务,两个进程之间的通信需要之前无需建立连接
UDP 套接字
- 对于使用无连接服务(UDP)的应用而言,套接字是2元组的一个具有本地意义的标示
- 2元组:IP,port(源端指定)
- UDP套接字指定了应用所在的一个端节点(end point)
- 在发送数据报时,采用创建好的本地套接字(标示ID),就不必在发送每个报文中指明自己所采用的ip和port
- 但是在发送报文时,必须要指定对方的ip和udpport

- 对于使用无连接服务(UDP)的应用而言,套接字是2元组的一个具有本地意义的标示
